Agent-to-Agent Architecture: When One AI Isn't Enough
Single-agent systems hit a ceiling. Multi-agent architectures, where specialized agents delegate, collaborate, and coordinate, are how complex AI workflows actually get built. Orchestration patterns, communication models, and the architecture decisions that matter.
Agent-to-Agent Architecture: When One AI Isn't Enough
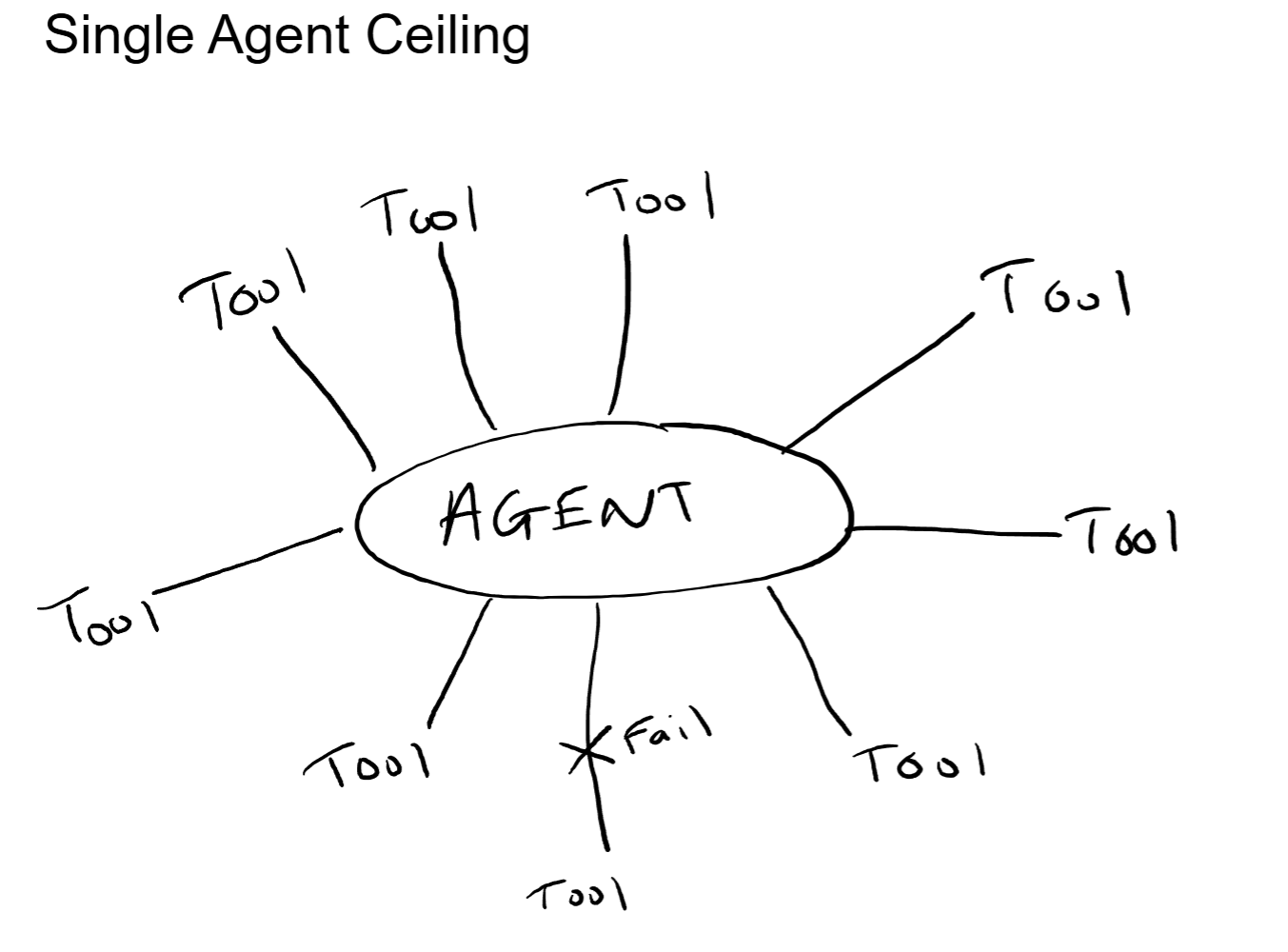
A single AI agent can do a lot. It can search the web, query a database, summarize a document, and draft an email. Ask it to do all of those things as part of one complex task, and the quality starts to fall apart. The context window fills up. Tool selection gets unreliable. One failure in the middle of a ten-step process brings the whole thing down.
The solution is not building a better single agent. It is building multiple agents that specialize and coordinate. One agent handles research. Another handles analysis. A third handles writing. A coordinator breaks the task apart, delegates the pieces, and assembles the final result.
This is multi-agent architecture, and it is how the most capable AI systems are being built today. This post covers the three primary patterns for multi-agent coordination, how agents communicate with each other, and the architecture decisions that determine whether a multi-agent system actually works in production.
Why Single Agents Hit a Ceiling
There are three walls that every single-agent system runs into as task complexity increases.
Context Window Overload
A single agent handling a complex task needs to hold everything in memory: every tool schema, every instruction, every intermediate result, the full conversation history. The context window is finite, and as it fills, the model's ability to focus on what matters degrades. Important details from early in the process get lost as newer information pushes them toward the edges of the window.
This is not a theoretical problem. It shows up the moment an agent needs to perform more than four or five steps sequentially. By step seven, the context window contains so much accumulated state that the model starts missing instructions it followed perfectly at step two.
Tool Sprawl
An agent with five well-defined tools performs significantly better at tool selection than an agent with fifty. As the number of available tools increases, the model's accuracy in choosing the right one for each step decreases. The model has to evaluate every tool description against the current subtask, and more options means more room for incorrect selection.
From a systems perspective, this is the same problem a monolithic application faces when it tries to do everything. Specialization improves performance. A single agent with every tool is a monolith. Multiple agents with focused toolsets are microservices.
Failure Cascading
When a single agent is executing a ten-step process and step seven fails, the entire process fails. There is no isolation. There is no fallback. There is no way to retry just the failed step without re-running everything that came before it.
In a multi-agent system, each agent handles a discrete subtask. If the research agent fails, the orchestrator can retry that specific subtask or route it to a fallback agent, without losing the work completed by other agents. Failure isolation is a fundamental architectural benefit.
For any enterprise deploying AI workflows, failure isolation directly impacts reliability. A customer-facing agent system that fails completely on one bad tool call is not production-ready. A system where failures are contained and retried transparently is.
Multi-Agent Patterns
There are three primary patterns for organizing multi-agent systems. Each makes a different tradeoff between control, flexibility, and complexity.
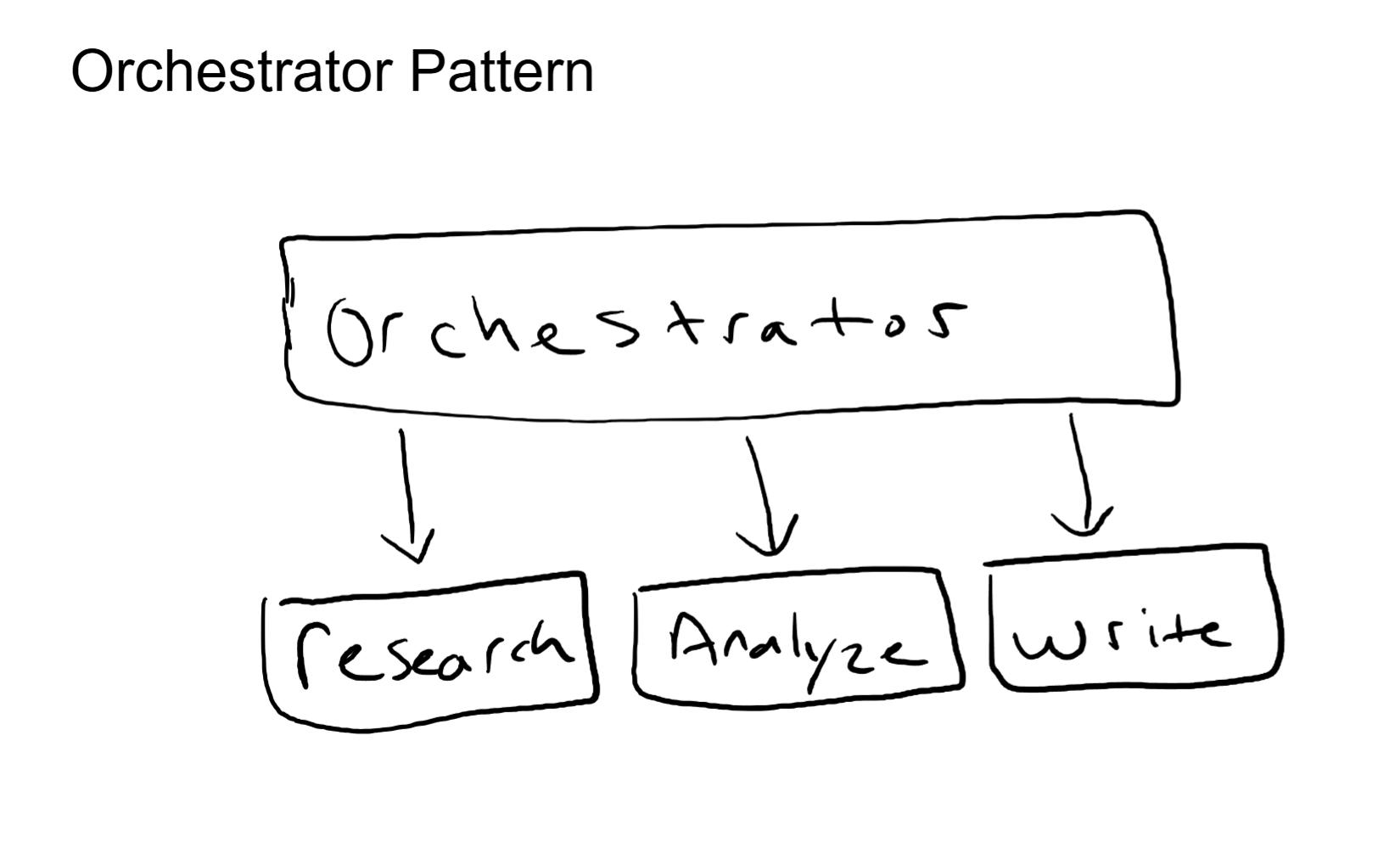
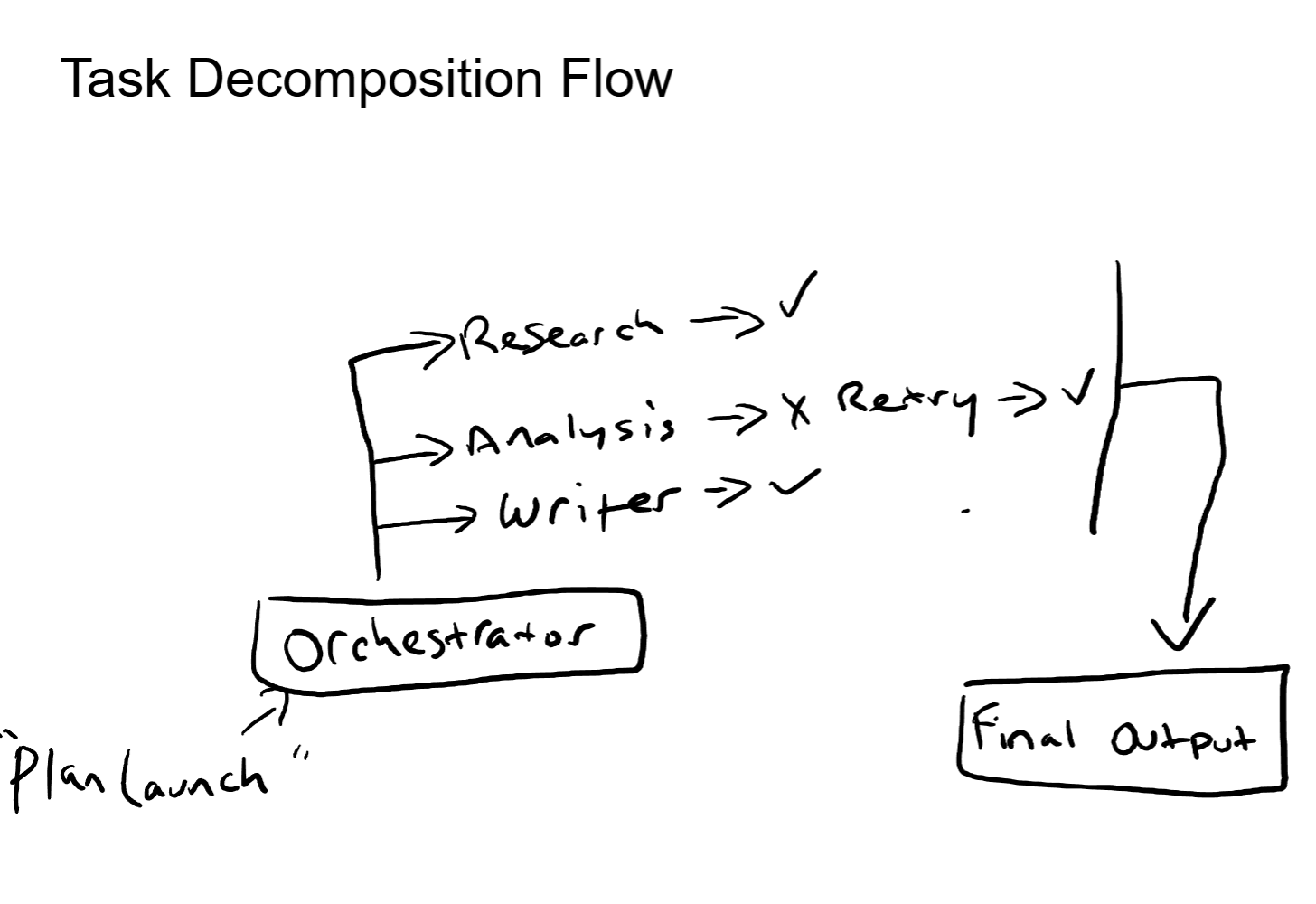
Pattern 1: Orchestrator + Workers
A central orchestrator agent receives the task, decomposes it into subtasks, and delegates each subtask to a specialized worker agent. Each worker has a narrow focus: a small set of tools, a focused system prompt, and a limited context scope. The worker executes its subtask and returns the result to the orchestrator. The orchestrator collects all results and synthesizes the final output.
This is the most common pattern in production multi-agent systems, and for good reason. The orchestrator handles decomposition and synthesis (high-level reasoning). The workers handle execution (focused, reliable task completion). Each worker's context window stays clean because it only sees its own subtask, not the entire project.
The tradeoff is that the orchestrator is a single point of coordination. If the orchestrator makes a bad decomposition decision (assigns the wrong subtask to the wrong worker, misses a dependency between subtasks), the downstream results suffer. The quality of the orchestrator's planning directly determines the quality of the overall output.
From an architecture standpoint, this is hub-and-spoke. The orchestrator is the hub. The workers are the spokes. If you have designed network topologies, you have already reasoned about the tradeoffs of this pattern: centralized control with a single point of failure at the hub.
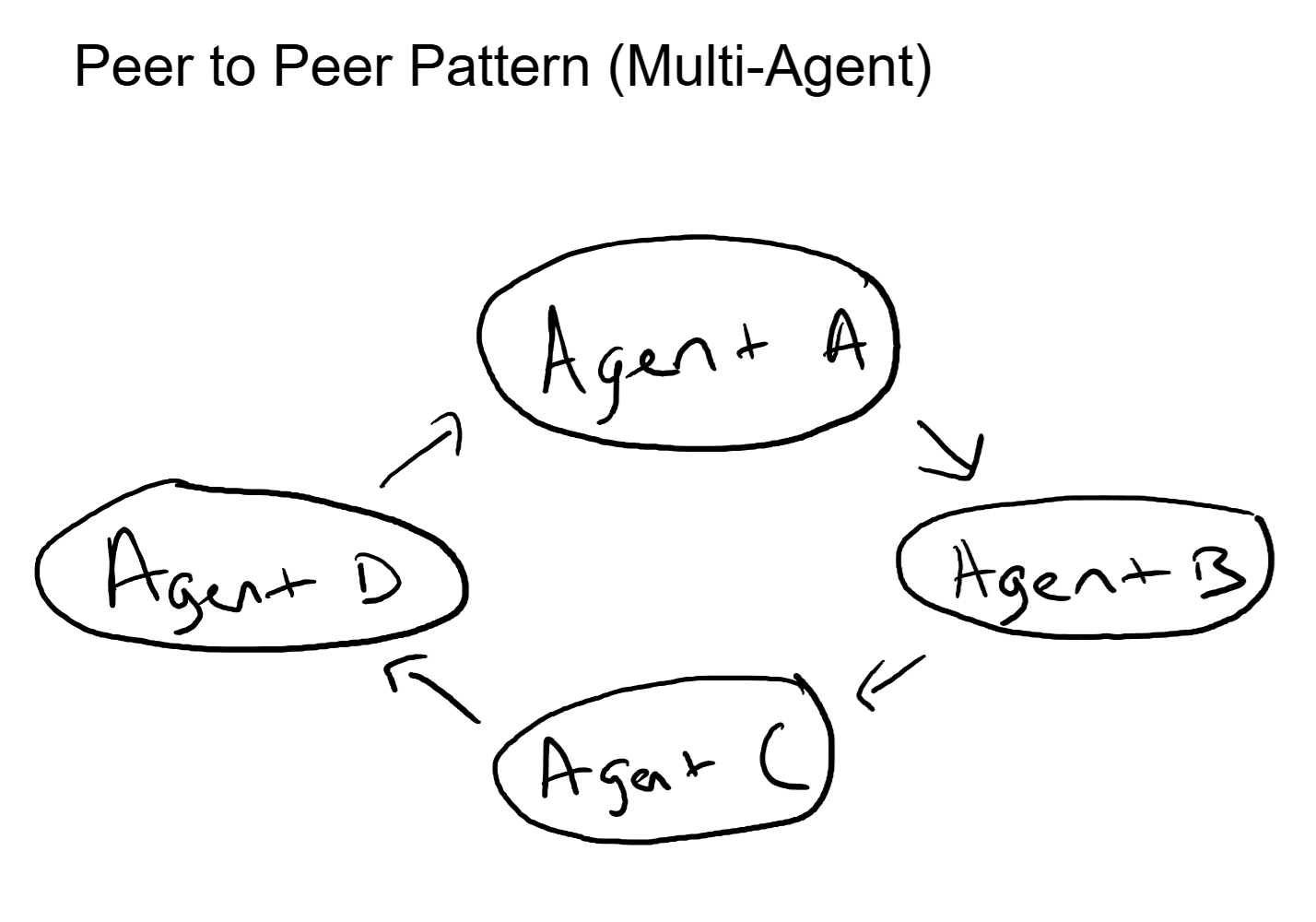
Pattern 2: Peer-to-Peer Mesh
No central orchestrator. Agents communicate directly with each other, passing context, requesting help, and sharing results laterally. Each agent decides when to invoke another agent based on its own assessment of the task.
This pattern is more flexible than orchestrator-worker. There is no single point of coordination failure. Agents can self-organize, splitting work dynamically as the task evolves. It works well when the agents are highly capable and the task structure is not predictable in advance.
The tradeoff is complexity. Without a central coordinator, there is no single place to look for the overall plan, no clear chain of accountability, and a real risk of circular delegation (Agent A asks Agent B, who asks Agent C, who asks Agent A). Debugging a peer-to-peer system requires tracing messages across multiple agents, which is significantly harder than reading an orchestrator's sequential plan.
This maps directly to a full-mesh network topology. Every node can reach every other node directly. Maximum flexibility, maximum path options, but also maximum complexity in managing the connections and preventing loops.
In practice, pure peer-to-peer agent architectures are rare in production. Most systems that start with this ambition end up adding a lightweight coordinator to prevent runaway delegation and provide observability. The pattern works best for teams of three to four highly specialized agents working on a loosely defined creative or analytical task.
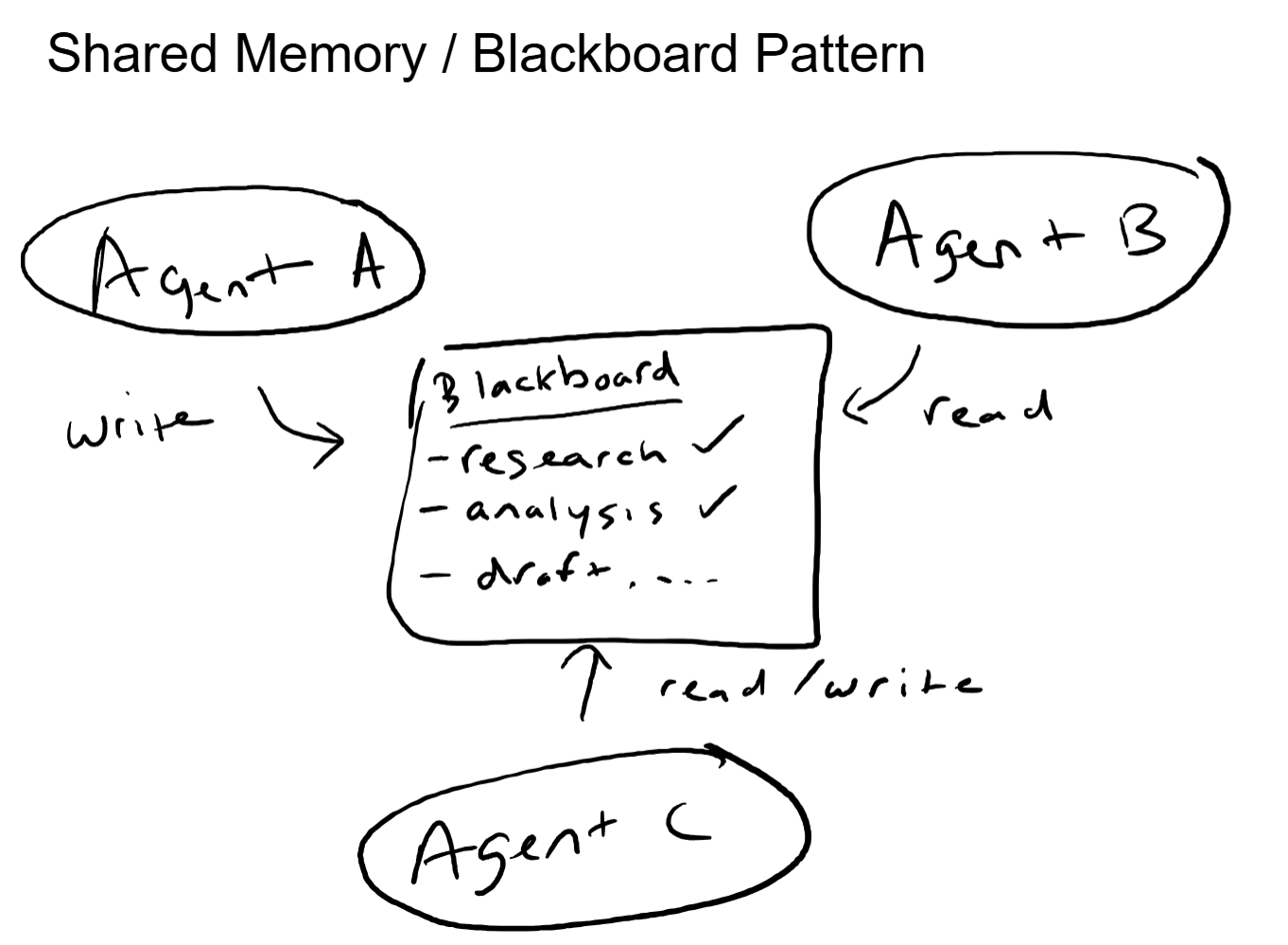
Pattern 3: Blackboard / Shared State
Agents do not talk to each other directly. Instead, they all read from and write to a shared state store, often called a "blackboard." Each agent monitors the blackboard for conditions relevant to its specialty. When relevant data appears, the agent picks up the task, performs its work, and writes the results back.
This is decoupled coordination. No agent needs to know which other agents exist or what they are doing. They only need to know what to look for on the blackboard and what to write back when they are done. Adding a new agent means deploying it with rules about what blackboard conditions trigger its work. No existing agents need to be modified.
The tradeoff is latency and sequencing. Because agents are not directly orchestrated, the system relies on polling or event triggers to notice when new data appears. The order of operations is implicit (Agent B waits for Agent A's output to appear) rather than explicit (Orchestrator tells Agent B to start after Agent A finishes). This can lead to timing issues and makes it harder to guarantee a specific execution sequence.
This pattern maps to a publish-subscribe message bus in distributed systems. Producers publish events, consumers subscribe to topics, and the bus handles delivery. The agents are loosely coupled through data rather than direct communication.
The blackboard pattern works well for systems where the workflow is not strictly sequential, where multiple agents can work in parallel on independent subtasks, and where the set of agents may change over time without requiring reconfiguration of the existing ones.
Communication: How Agents Actually Talk
Regardless of which pattern you use, the quality of a multi-agent system depends on how agents pass information to each other. Three design decisions dominate this.
Structured Message Passing
Agents communicate via structured messages, not natural language prose. A task delegation is a structured object with fields: task description, expected output format, relevant context, constraints. A result is a structured object with fields: status, output data, confidence level, any errors encountered.
Natural language handoffs (one agent writing a paragraph that another agent reads and interprets) are unreliable. Information gets lost in translation. Intent gets misinterpreted. Structured schemas ensure that every handoff preserves the critical details.
Context Handoff Strategy
When Agent A delegates to Agent B, what context does Agent B receive? This is one of the most consequential design decisions in multi-agent architecture.
Passing everything (the full conversation history, all prior results, every piece of context) wastes context window space in the worker agent and can actually hurt performance. The worker gets flooded with irrelevant information and loses focus on its specific subtask.
Passing too little means the worker agent lacks the context to do its job well. It produces generic output because it does not understand the broader goal.
The effective approach is surgical context: pass the specific inputs the worker needs, a clear description of the subtask, the expected output format, and only the prior results that are directly relevant. Everything else stays with the orchestrator.
This is the same principle behind good API design. An endpoint should receive exactly the parameters it needs to do its job, not a dump of the entire application state.
Error Propagation
What happens when a worker agent fails? There are several options, and the choice needs to be explicit:
- Retry: The orchestrator sends the same subtask to the same worker again, possibly with adjusted context.
- Fallback: The orchestrator routes the subtask to a different worker agent (a backup specialist).
- Escalate: The failure gets surfaced to a human reviewer for manual handling.
- Skip and continue: The orchestrator proceeds without the failed subtask's result and adjusts the final synthesis accordingly.
The worst option is no strategy at all, which is what happens by default. Without explicit error handling, a single worker failure silently corrupts the entire output because the orchestrator has no mechanism to detect and respond to the problem.
The Networking Angle
Every multi-agent pattern has a direct parallel in network topology design.
Orchestrator pattern is hub-and-spoke. One central node coordinates all traffic. Simple to manage, easy to monitor, single point of failure. The hub's capacity limits the system's throughput. Same tradeoffs, same mitigations (redundant hubs, failover).
Peer-to-peer pattern is full mesh. Every node can reach every other node directly. Maximum path diversity, no single point of failure, but O(n-squared) complexity in managing connections. Routing loops are a real risk without careful protocol design. The same is true for agent delegation loops.
Blackboard pattern is publish-subscribe. Agents publish results to a shared bus and subscribe to events relevant to their specialty. Loose coupling, easy to add new agents, but event ordering and delivery guarantees become the hard engineering problems. Same challenges as message queue design in distributed systems.
Error propagation is spanning tree reconvergence. When a link fails in a network, spanning tree detects the failure and reconverges around it. The network adapts. Multi-agent error handling is the same concept: detect the failure, reroute the task, continue operating with the remaining agents. If you have debugged a spanning tree loop, you understand why explicit failure handling in multi-agent systems is non-negotiable.
Context handoff is packet fragmentation and reassembly. The orchestrator breaks the full task context into fragments sized appropriately for each worker (fragmentation). The workers process their fragments and return results. The orchestrator reassembles everything into a coherent final output (reassembly). Too-large fragments overwhelm the worker. Too-small fragments lose critical context. Finding the right size is the same engineering problem in both domains.
Real-World Architecture Decisions
How Many Agents?
Start with the minimum number of agents that gives you meaningful specialization. For most systems, that is three to five. Split an agent into two only when a single agent is demonstrably overloaded: too many tools, too much context, or too broad a responsibility.
More agents means more coordination overhead, more handoff points where information can be lost, and more failure surfaces. The goal is not maximum agents. The goal is the right level of specialization for the task complexity.
Shared vs Isolated Memory
Should agents share a common memory store, or should each maintain its own? Shared memory (the blackboard approach) makes coordination easier but introduces the risk of race conditions and conflicting writes. Isolated memory keeps each agent's state clean but requires explicit handoffs for every piece of shared information.
For most orchestrator-worker systems, isolated memory with structured handoffs is the more reliable approach. Each agent owns its own context. The orchestrator passes exactly what each worker needs and collects exactly what each worker produces.
Human-in-the-Loop
Not every decision should be autonomous. Multi-agent systems need explicit checkpoints where a human can review, approve, or redirect.
The effective pattern is: agents propose, humans approve for high-stakes actions. The agent generates the analysis. The agent drafts the recommendation. But before the agent sends the customer email, executes the financial transaction, or publishes the content, a human reviews and signs off.
Where you place these gates depends on the risk tolerance of the workflow. Low-risk, high-volume tasks (internal research summaries) can run fully autonomous. High-risk, high-visibility tasks (customer-facing communications, financial decisions) need human checkpoints at critical steps.
Key Takeaways
- Single agents have three ceilings: context window overload, tool selection degradation, and failure cascading. Multi-agent architecture addresses all three through specialization and isolation.
- Three patterns dominate: Orchestrator-worker (hub-and-spoke), peer-to-peer (full mesh), and blackboard (publish-subscribe). Each makes a different tradeoff between control, flexibility, and complexity.
- Communication design is the hardest part. What context to pass, how to structure handoffs, and how to handle failures matters more than which pattern you choose. Structured messages over natural language. Surgical context over full dumps.
- Start simple, split when necessary. Three to five agents with clear specializations is a strong starting point. Add agents only when an existing one is demonstrably overloaded.
- Humans belong in the loop. Agents propose, humans approve for high-stakes decisions. The placement of approval gates is a business risk decision, not a technical one.
Up Next
You have seen MCP for tool access and multi-agent patterns for coordination. But how do agents from different systems, different vendors, and different frameworks talk to each other? The next post covers the emerging world of agent-to-agent interoperability protocols, where standardized discovery and communication enable agents that were never designed to work together to collaborate across organizational boundaries.