Prompt Caching and Sticky Routing: How Providers Slash Costs at Scale
When millions of users share similar prompts, smart caching and routing eliminate redundant computation. How shared system prompt caching, sticky session routing, and prefill/decode splitting work behind the scenes.
Prompt Caching and Sticky Routing: How Providers Slash Costs at Scale
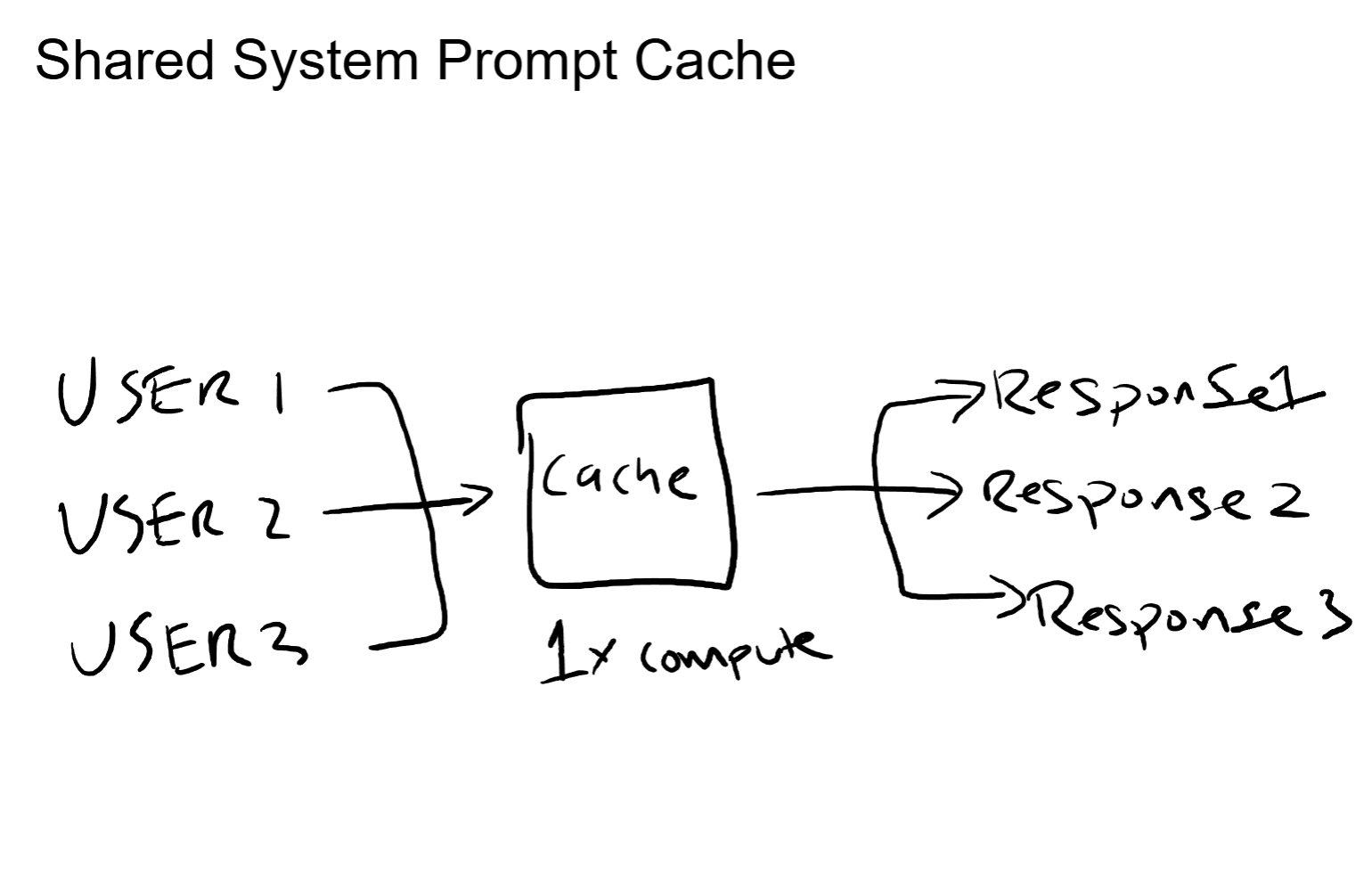
Ten thousand people ask ChatGPT a question in the same minute. Every single one of those requests starts with the same hidden system prompt, the same set of instructions the model reads before it even looks at the user's message. Does the system process that identical system prompt ten thousand times? No. It processes it once and reuses the result for the other 9,999 requests.
That single optimization, shared prompt caching, is one of three infrastructure patterns that have driven API prices down by orders of magnitude over the past two years. The other two are sticky routing (keeping your requests on the same server to maximize cache hits) and prefill/decode splitting (using different hardware for different parts of the generation process).
None of these change what the model knows or how it reasons. They change how efficiently the infrastructure serves the model's output. And from a cost perspective, these are the optimizations that determine whether serving AI at scale is financially viable.
Shared System Prompt Caching
The Observation That Makes This Work
Every conversation with a hosted LLM starts with a system prompt. For ChatGPT, that system prompt contains instructions about behavior, tone, safety guidelines, and capabilities. It is identical across millions of concurrent conversations.
For API users, the pattern is the same. If your application sends a system prompt that says "You are a customer support agent for Acme Corp. Follow these guidelines..." then every user session starts with that exact same text. Hundreds or thousands of requests per minute, all beginning with the same prefix.
Processing that prefix means running it through every layer of the model, computing the attention keys and values (the KV activations) for each token. That is the most compute-intensive part of handling a request. And if the prefix is the same every time, computing it more than once is pure waste.
The Optimization
Cache the KV activations for shared prefixes. The first request computes them. Every subsequent request that starts with the same system prompt skips the prefix computation entirely and jumps straight to processing the unique part: the user's actual message.
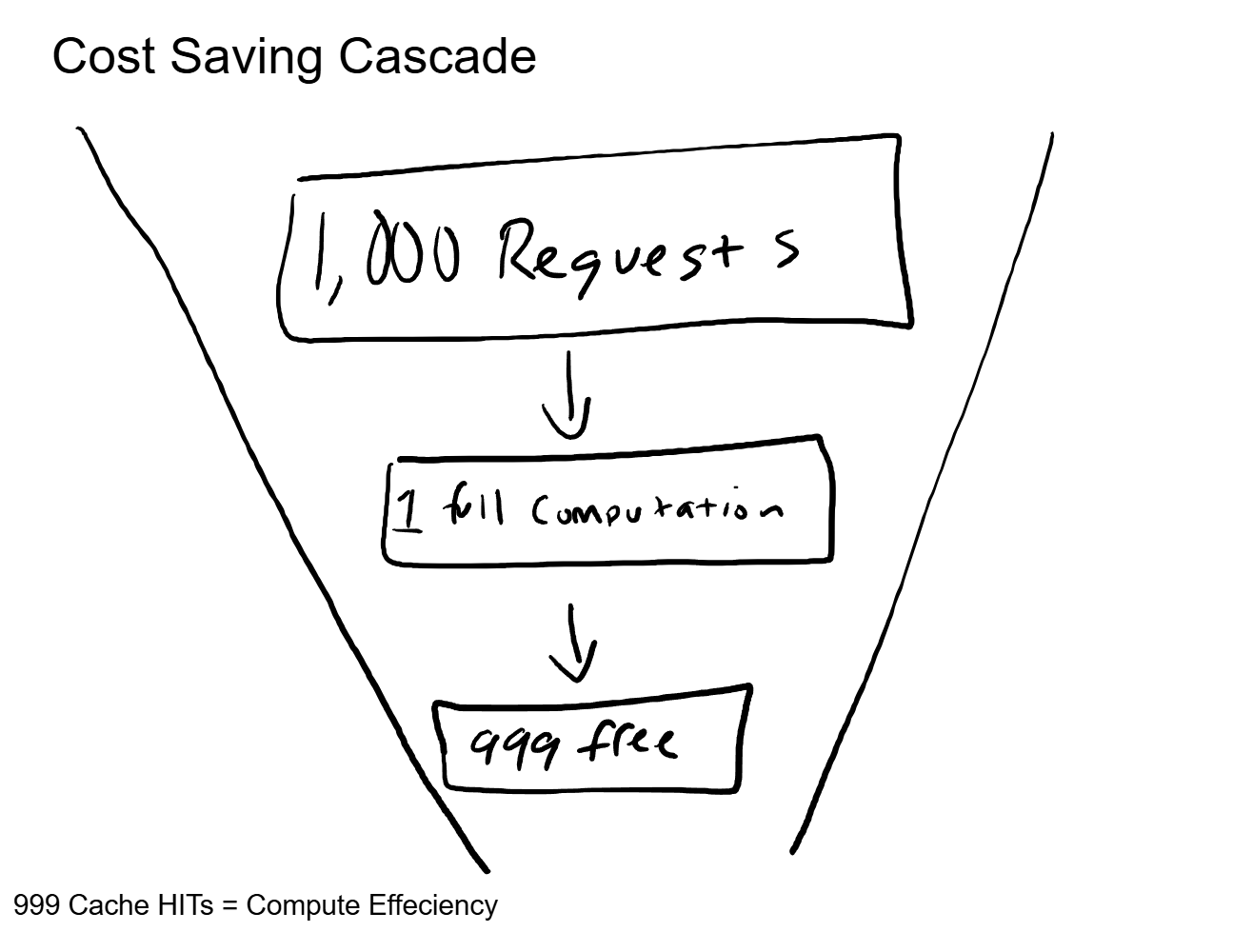
The math on this is straightforward. If your system prompt is 2,000 tokens and the user's message is 200 tokens, caching the prefix means you only compute 200 tokens instead of 2,200. That is a 90% reduction in prefill compute for every cached request.
At scale, this compounds dramatically. A thousand concurrent users sharing the same system prompt means 999 prefill computations that never happen. Those are GPU cycles that get freed up to serve more users, which is how providers increase throughput without adding hardware.
For any business running agents or AI applications through an API, this is why longer, more detailed system prompts do not cost proportionally more at scale. The first request pays the full price. Every subsequent request with the same prefix gets a discount that approaches free.
Sticky Routing: Keep My Requests on the Same Node
The Problem with Random Load Balancing
Standard load balancing distributes requests across servers to spread the workload evenly. In web applications, this is fine because most requests are stateless. But LLM inference is not stateless in practice.
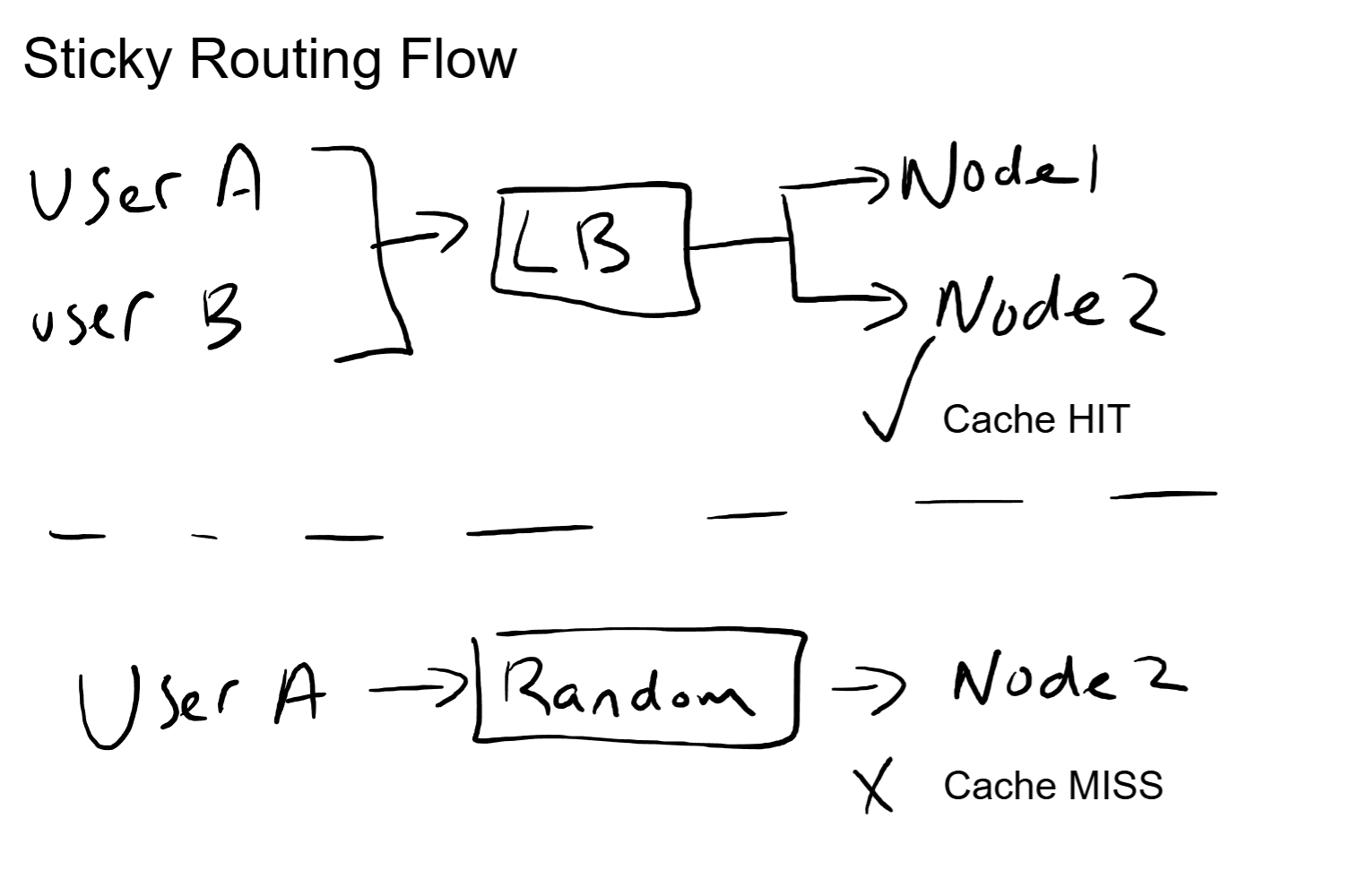
When you send your first message, the inference node computes and stores the KV cache for your conversation. Your system prompt, your first question, the model's response: all of that context lives in the KV cache on that specific node.
If your second message gets routed to a different node, that KV cache does not exist there. The new node has to recompute everything from scratch: the system prompt, the full conversation history, all of it. That is a cache miss, and it means paying the full prefill cost again for context the system already processed.
For a multi-turn conversation, this adds up fast. By turn five, a cache miss means reprocessing four previous turns of dialogue plus the system prompt. That is significant wasted compute, and it translates directly to higher latency for the user.
The Solution: User-Aware Routing
Take the user's account ID, session ID, or some stable identifier and hash it to a preferred server. The same user always lands on the same inference node. Same node means same KV cache. Same KV cache means cache hits on every subsequent turn.
This is not a new concept. Anyone who has worked with web infrastructure recognizes it immediately: it is session persistence. Cookie-based affinity, IP hash routing, sticky sessions. The same pattern that web load balancers have used for decades, applied to LLM inference.
The implementation details vary by provider, but the architecture is consistent. The routing is almost certainly not IP-based (users change networks constantly). It is more likely tied to account or session identifiers mapped to a preferred node list, with fallback nodes for when the primary is at capacity.
From an infrastructure perspective, sticky routing introduces a tradeoff. It improves cache hit rates, but it can create uneven load distribution. If one user generates far more requests than average, their assigned node carries a disproportionate load. The balancing act between cache efficiency and load distribution is a real operational concern at scale.
Prefill vs Decode: Two Jobs, Two Types of Hardware
They Are Not the Same Workload
Generating a response from an LLM involves two distinct phases, and they stress hardware in completely different ways.
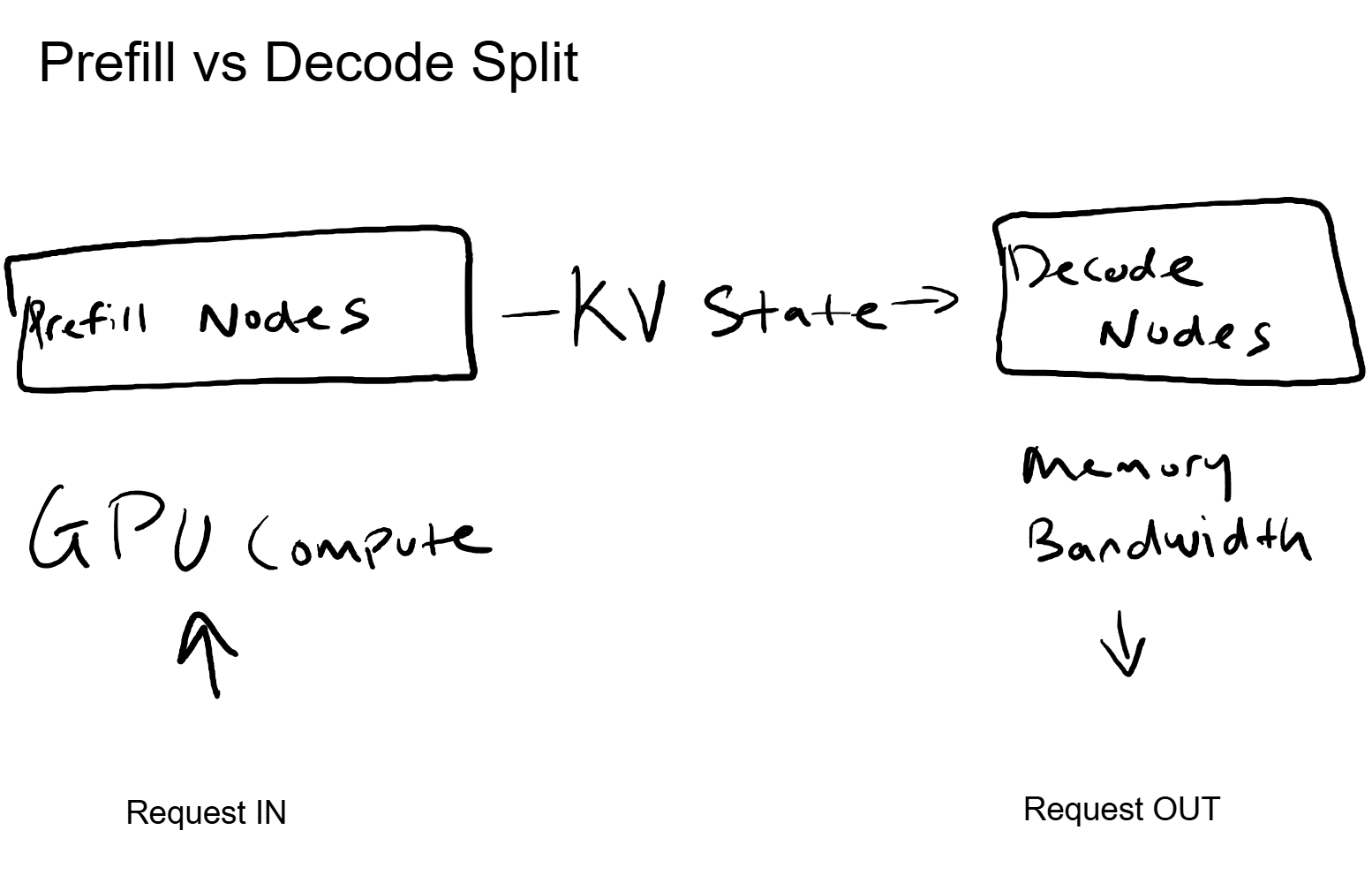
Prefill is the first phase. The model processes the entire input (system prompt, conversation history, user message) all at once. This is compute-intensive work: massive matrix multiplications running through every layer of the model. Prefill wants raw GPU compute power. More FLOPS, faster processing.
Decode is the second phase. The model generates output tokens one at a time, each one dependent on the previous. For each new token, the model reads from the KV cache to apply attention across all prior context. This is memory-bandwidth-intensive work. Decode wants fast memory access, not raw compute. The GPU spends most of its time reading data, not crunching numbers.
Here is the key part. These two phases have opposite hardware profiles. Prefill is compute-bound. Decode is memory-bound. Running both on the same GPU means that GPU is poorly utilized for at least one of the phases at any given time.
Disaggregated Serving
The solution is to split them onto separate hardware pools optimized for each task.
Prefill nodes get GPUs optimized for raw compute throughput. They process incoming prompts, compute the KV activations, and hand off the state. Decode nodes get GPUs (or configurations) optimized for memory bandwidth. They receive the KV state from the prefill node and generate tokens efficiently.
The request flow becomes: user sends a message, the prefill pool processes the input, the KV state transfers to a decode node, and the decode node streams back the response token by token.
This separation means both hardware pools run at higher utilization. The prefill nodes are always doing compute-heavy work. The decode nodes are always doing bandwidth-heavy work. No GPU sits idle waiting for work that matches its strengths.
For the business running the infrastructure, this is a direct cost efficiency lever. Better hardware utilization means more requests served per dollar of GPU spend. It is also why you see different pricing for input tokens versus output tokens in most API pricing models: the infrastructure cost for processing them is genuinely different.
The Networking Angle
Every one of these patterns has a direct parallel in network infrastructure.
Sticky routing is session persistence. It is the same architecture as a load balancer with cookie affinity or source-IP hash. The goal is identical: keep a stateful session on the same backend to avoid recomputing state. The failure modes are identical too. If the target node goes down, the session state is lost and has to be rebuilt from scratch.
Prefill/decode splitting is the same concept as separating control plane and data plane processing in a router. The control plane handles the compute-heavy work of building routing tables, running protocols, making forwarding decisions. The data plane handles the bandwidth-heavy work of moving packets at line rate. Different workloads, different silicon, same device. LLM serving arrived at the same architectural conclusion for the same reasons.
Prompt caching is a content delivery pattern. A CDN caches static assets at the edge so the origin server does not recompute or re-serve them for every request. Shared system prompt caching does the same thing: the "static asset" is the KV activation for a common prefix, and the "CDN" is the inference node's GPU memory.
If you have spent time designing network infrastructure, you have already internalized the principles behind these optimizations. The domain is different. The engineering logic is the same.
The Business Impact
These three optimizations are the primary reason API prices have dropped so aggressively. The cost of the underlying GPU hardware has not changed dramatically. What has changed is how efficiently that hardware gets used.
Prompt caching means the same GPU serves more users by skipping redundant computation. Sticky routing means conversation state is reused instead of rebuilt. Disaggregated serving means each GPU runs workloads matched to its strengths instead of sitting partially idle.
The compounding effect is significant. A system that implements all three can serve the same traffic on a fraction of the hardware compared to a naive implementation that processes every request from scratch, routes randomly, and runs both phases on the same GPU.
For enterprises evaluating AI costs, this context matters. When a provider drops prices, it is not because they are taking a loss. It is because their serving infrastructure got more efficient. Understanding these patterns helps you evaluate whether a provider's pricing is sustainable and where the cost floor actually sits.
Key Takeaways
- Shared prompt caching eliminates redundant computation. Identical system prompts get processed once. Every subsequent request with the same prefix reuses the cached KV activations, cutting prefill compute by up to 90% or more.
- Sticky routing maximizes cache reuse across conversation turns. Routing the same user to the same inference node ensures the KV cache from prior turns is available, avoiding expensive recomputation of full conversation history.
- Prefill and decode have opposite hardware profiles. Prefill is compute-bound. Decode is memory-bandwidth-bound. Splitting them onto specialized hardware pools increases utilization and reduces cost per request.
- These are web-scale infrastructure patterns applied to AI. Session persistence, CDN-style caching, control/data plane separation. The principles are decades old. The application to LLM serving is new.
- This is why prices keep dropping. Not cheaper GPUs. Smarter utilization of the GPUs that already exist.
Up Next
The next post in this series covers attention mechanisms and the KV cache: why every token gets more expensive as conversations grow, how the KV cache works as a memory system, and the engineering tradeoffs behind context window sizes.